
The Cantos contain a graph. Not an x-axis y-axis plot, but a collection of nodes and edges. For example, nodes are names (Homer, Ovid, Dante, Sordello, Sigismundo, the Major H.C. Douglas) and the connection between nodes (i.e. edges) could be reference. All the names mentioned are referenced by The Cantos.
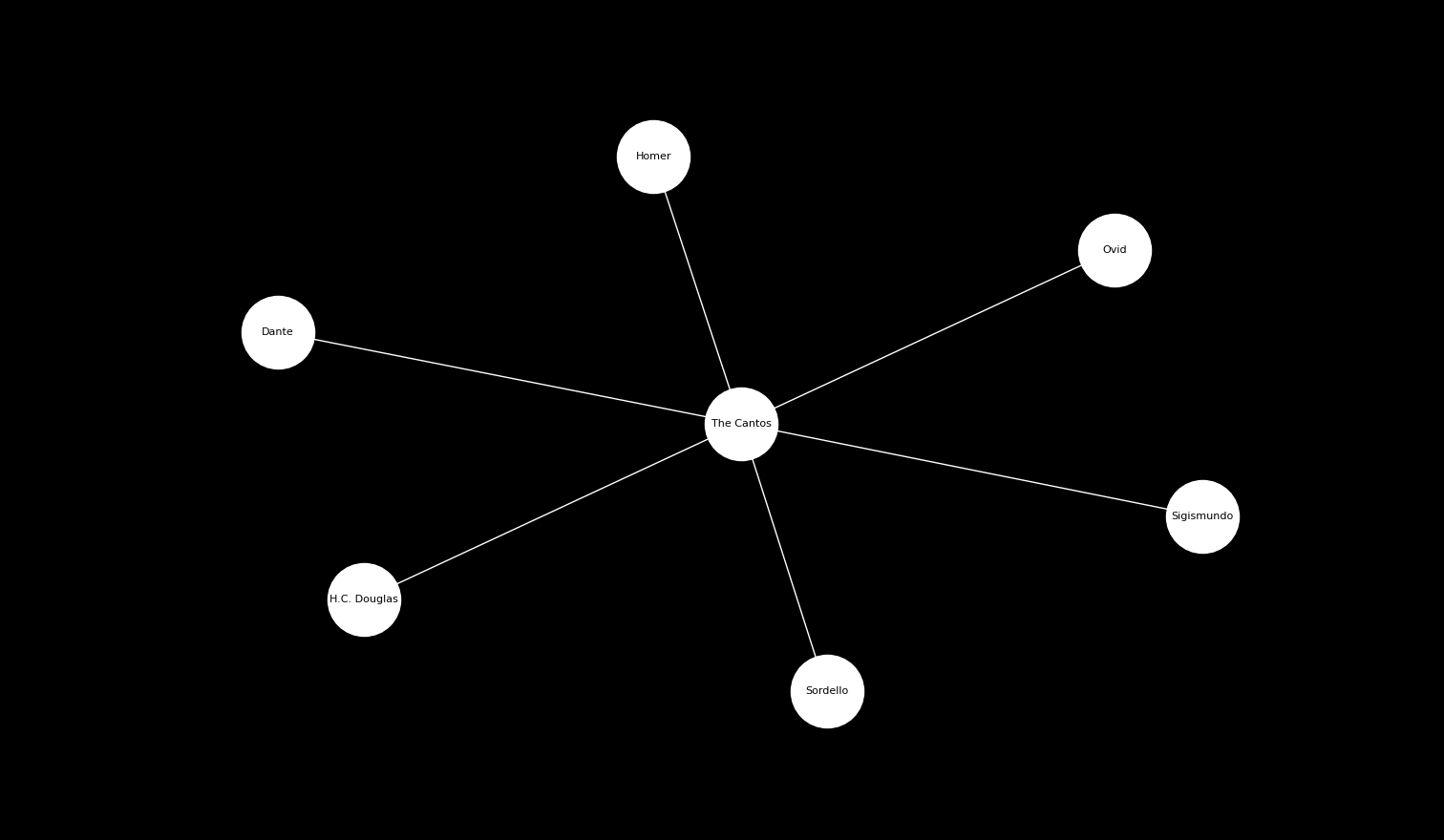
We also have edges between non-Canto nodes. Homer and Ovid are also mentioned in Dante’s Divine Comedy (alongside Horace and Lucan, who invite the character Dante into the Elysian Fields). Therefore we have The Cantos—Homer, T.C.—Ovid and T.C.—Dante, as well as Dante—Homer and Dante—Ovid.
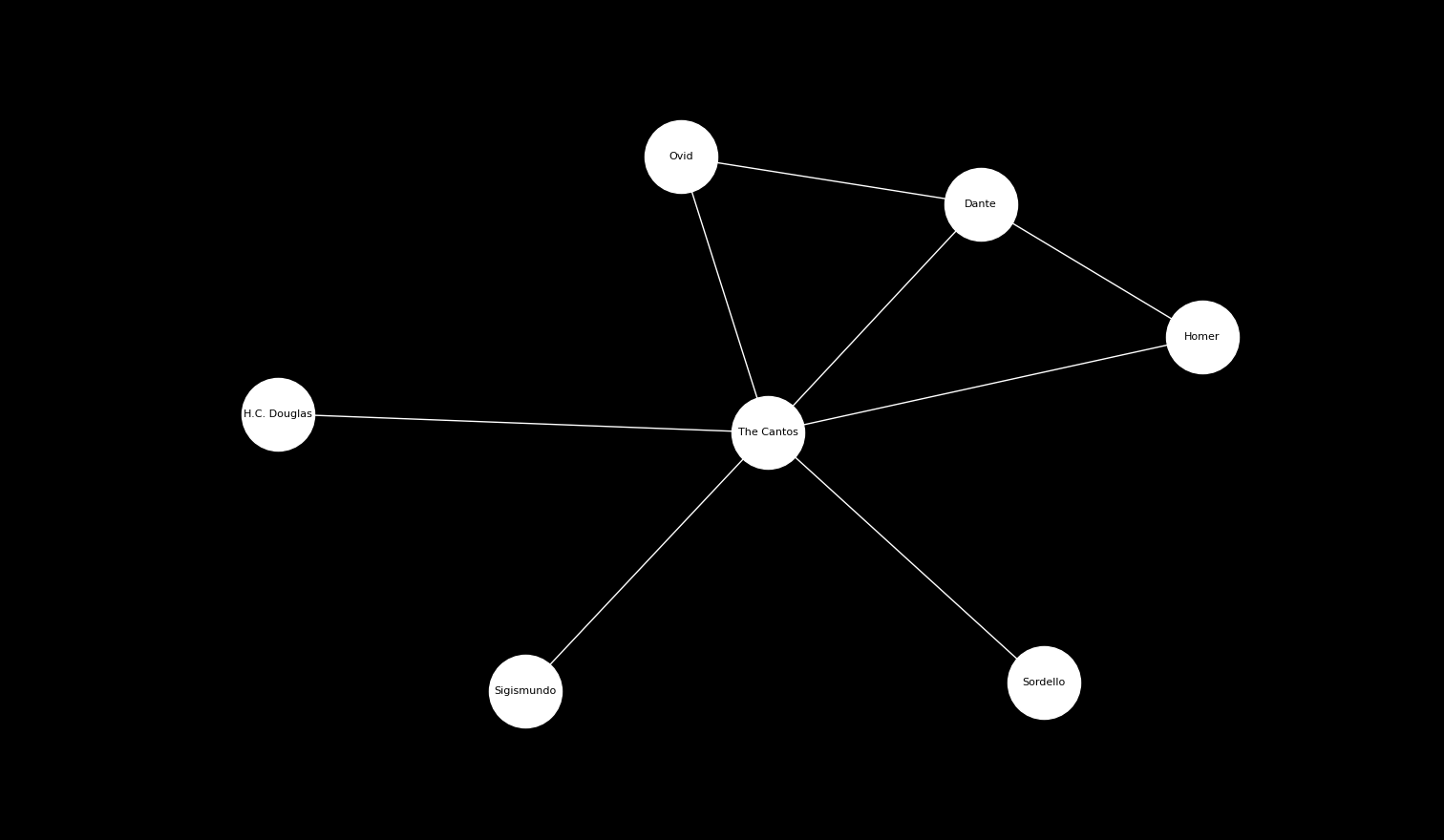
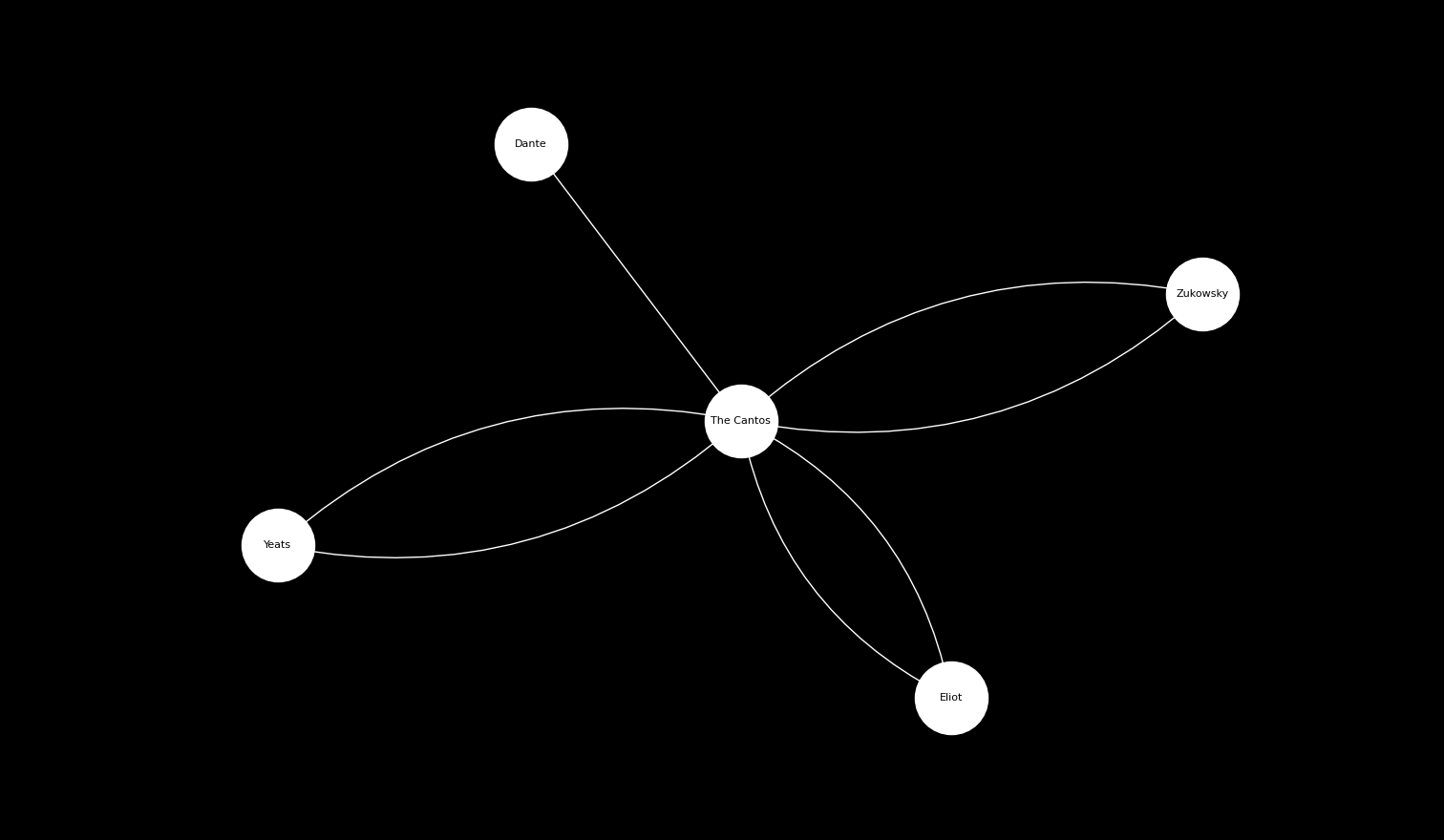
Then there is the matter of Pound’s contemporaries. The Cantos influence Zukowsky, Eliot, Yeats as Zukowsky, Eliot and Yeats influence The Cantos. So we are given small cycles (or bi-directional edges) around contemporaries.
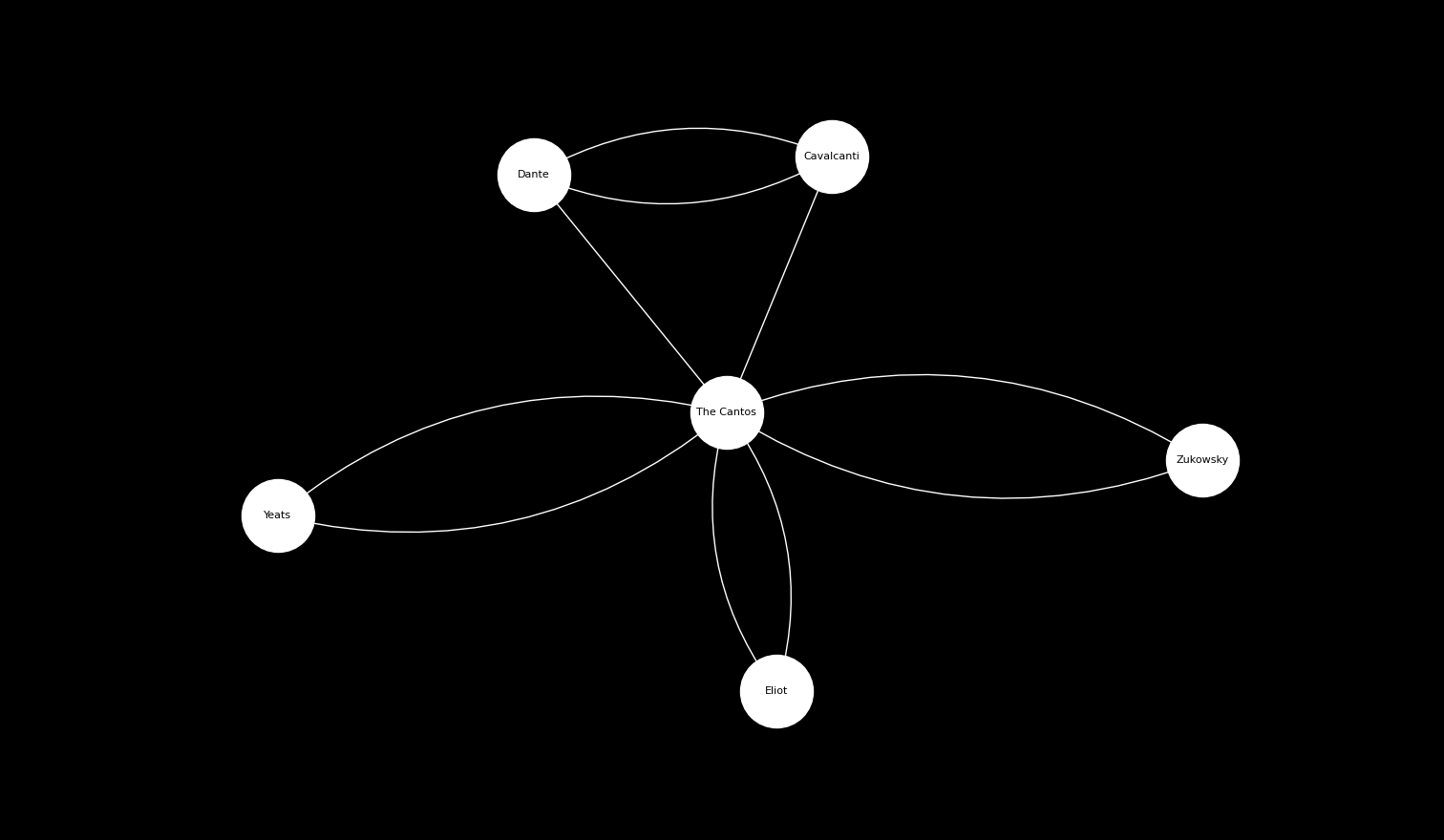
And we can complicate the notion of influence among contemporaries by considering non-Canto nodes again.
Then there is the scholarship, and scholarship that relies on scholarship. If with an AI we were automatically processing scholarship we might also like to make measurements of it. Part of the process is error correction. We know that Edwards and Vasse’s The Annotated Index to The Cantos contains mistakes — hence we have Terrell’s Companion and The Cantos Project — and if a piece of scholarship relies on The Annotated Index, we might like to trust that scholarship less until we can ascertain that it does not propagate a mistake. (This treatment of scholarship being highly objective, I should mention that one of my favourite pieces of Poundian scholarship is Alice Steiner Amdur’s.)
We can generate these graphs not only for The Cantos, but per-Canto. Then we can make inter-Canto comparisons and look for progressions. For example, part of the charm of Canto I is the Pound—Divus—Homer path. Does another Canto contain a similar path? Which Cantos share the same references?
We could also give the connection between nodes a different metric, other than reference. Let us say association. Peire Vidal (troubadour) and Ovid get mentioned next to each other a lot in The Cantos. Why? Does it matter? Does it change? Does the ‘why’ change? And who else has this kind of relationship? We can start by weighting edges between nodes based on instances of locality and respond to our measurements by considering associations under the aforementioned ideogrammic comparison method, or ‘cross-light’.
And we can extend the central node of The Cantos towards Pound by including his other works, his prose, his letters, his radio speeches. Here we might like to iterate our observations per-year, or per-opusculum, but we should start with the simple, The Cantos.
Before we measured dromena and epopte and plotted it per-line per-Canto. This alternative data structure (nodes and edges) enables us to isolate elements of The Cantos before making measurements. I have given two or three example metrics, and there is scope for creativity. The Cantos lend themselves to this kind of treatment, this collection of tiny measurements. It is like turning the “great ball of crystal” in your hands and observing it from different directions. Though the page stuff is kaleidoscopic, when we step back we begin to see Pound as vortex. I wonder whether Pound shared this perspective (alongside chung) in his defeat,
That I lost my center
fighting the world.